Slack, Teams, courriels : les alertes critiques se mélangent aux conversations, memes et notifications de builds qui ont échoué. Quand ça sonne, impossible de savoir si c'est urgent.
TI et support IT
Fini les alertes perdues dans le bruit
IPA agit comme couche de distribution intelligente entre vos outils de monitoring (Zabbix, Datadog, Nagios, SOC) et vos techniciens. App dédiée avec sonnerie distinctive, cascade automatique, calendriers self-service — chaque alerte arrive à la bonne personne, au bon moment, avec garantie de prise en charge.
Les défis du secteur
Notre réponse
App dédiée, sonnerie distinctive
Quand ça sonne IPA, c'est critique. Sonnerie spécifique au choix, passe outre silencieux et Ne pas déranger, visible sur l'écran de veille. Plus de confusion avec Slack qui buzz toutes les 5 minutes pour rien.
Calendriers de garde sur Google Calendar, Excel, Slack — chaque équipe son système. Substitutions perdues dans les messages. Personne ne sait exactement qui est en ligne à 3h du matin.
Calendriers et gardes self-service
Chaque technicien gère son calendrier depuis l'app : groupes d'appartenance, périodes de disponibilité, bouton ON/OFF pour s'indisposer temporairement. L'admin voit tout en direct, substitutions en 1 clic.
Dizaines d'alertes par jour depuis la supervision, le cloud, le SOC. Dans le flux, les vraies urgences se perdent et les équipes finissent par ignorer les notifications — puis la vraie panne se noie dans le bruit.
Distribution intelligente, plus de bruit
IPA route chaque alerte au bon groupe (support, réseau, infra, cybersécurité) selon le type, l'horaire, la garde active. Le technicien ne reçoit QUE ce qui le concerne. Plus de flux d'alertes génériques à trier.
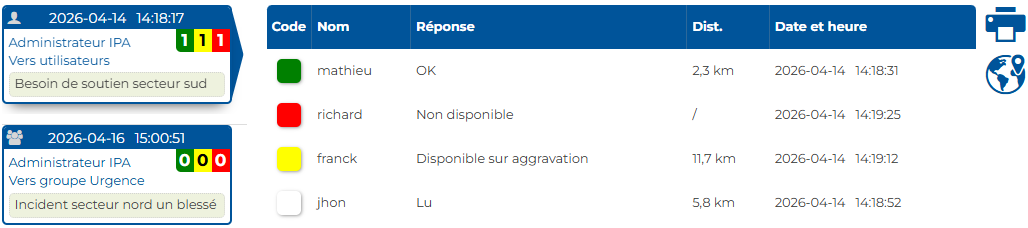
Une alerte part par courriel. Vue ? Par qui ? Quand ? Si personne ne répond, qui prend le relais ? Souvent on apprend le lendemain que la panne a duré 2h sans intervention.
Statut Reçu / Lu / Répondu + cascade
Chaque alerte remonte son statut en temps réel. Si le technicien de garde ne répond pas dans le délai fixé, cascade automatique vers le suivant, puis vers un autre groupe, et en dernier recours vers l'administrateur. Aucune alerte critique ne reste sans réponse.
Zabbix, Nagios, Datadog, PRTG, CloudWatch, sondes SOC : chacun alerte différemment. Comment unifier sans tout recâbler ?
Courriel et webhook universels
Chaque groupe IPA a son courriel dédié et son webhook. Pointez-y vos outils existants (Zabbix, Datadog, SOC) sans changer votre stack. Pas de migration, pas d'intégration lourde : ça marche en 10 minutes.
Une panne ou une intrusion à 3h, le bon technicien
en quelques secondes
-
Détection
Votre monitoring (Zabbix) ou votre SOC détecte l'incident à 3h12. Courriel ou webhook envoyé au groupe concerné (Infrastructure, Cybersécurité).
-
Routage intelligent
IPA identifie l'équipe de garde active (calendrier à jour), route l'alerte au technicien en astreinte. Notification sonnerie dédiée, passe outre silencieux et DND.
-
Prise en charge
Technicien confirme d'un clic depuis la notification : « J'arrive ». Statut remonte au dashboard. Il ouvre son VPN, règle le problème.
-
Cascade si silence
Pas de réponse en 3 minutes ? Cascade auto vers la relève, puis l'équipe entière. Si personne ne confirme, l'administrateur est alerté en dernier recours. Historisé pour le post-mortem.
Webhook, API, intégrations — entrant, sortant, sur mesure
IPA s'intègre aux deux sens de votre chaîne d'outils. Ni plus ni moins que ce qu'il vous faut.
Webhook entrant
URL dédiée par groupe. Recevez des alertes depuis Zabbix, Datadog, sondes SOC, scripts cron, applications maison.
Webhook sortant
IPA notifie vos systèmes externes (Jira, ServiceNow, Slack, Teams, scripts) à chaque statut : prise en charge, escalade, clôture.
Courriel dédié
Pour les outils qui alertent par courriel (SCADA, sondes basiques, crons). Traité exactement comme un webhook.
Intégrations sur mesure
Vous avez un système interne unique ? Notre équipe vous accompagne pour construire l'intégration adaptée.
Un cas d'intégration particulier ?
Vous avez un outil métier, un logiciel maison, une sonde propriétaire ? Décrivez-nous votre besoin en entrée ou en sortie — notre équipe construit l'intégration sur mesure avec vous.
Une alerte, un geste, une intervention
L'application accompagne chaque rôle IT — technicien, chef d'équipe, admin — de la notification à la résolution de l'incident :
- Alarme qui perce. Sonnerie dédiée au choix, vibration forte, passe outre silencieux et Ne pas déranger. SMS et appel vocal en secours si l'app ne répond pas.
- Acquitter en un geste. Depuis la notification : « J'arrive » / « En cours » / « Non dispo ». Pas besoin d'ouvrir l'app ni de se connecter.
- Suivi d'incident live. Statut de l'équipe en temps réel, qui résout quoi, escalades automatiques. L'admin peut déclencher une alerte depuis son app, sans passer par la console.
- Gestion personnelle. Mes groupes TI (réseau, infra, cybersécurité), calendrier d'astreinte, bouton ON/OFF pour congé ou formation.
- Droits d'accès par rôle. Technicien, chef d'équipe, admin TI, superviseur — chacun voit et fait ce que son rôle autorise.
Alarme qui perce
Même sur silent / DND
- Sonnerie dédiée
- Passe silent + DND
- SMS & vocal en secours
Acquitter en 1 geste
Depuis la notification
- J'arrive / En cours / Non dispo
- Pas besoin d'ouvrir l'app
- Ni de se connecter
Suivi incident live
Dashboard de poche
- Statut équipe en direct
- Qui résout quoi
- Historique complet
Gestion perso
Depuis son téléphone
- Mes groupes TI
- Calendrier astreinte
- Bouton ON / OFF
Droits d'accès par rôle
technicien · chef d'équipe · admin TI · superviseur
< 30 s
de la détection de l'incident à la notification du technicien de garde actif — cascade automatique si pas de réponse
Fonctions IPA activées sur ce secteur
Questions fréquentes
Quels outils de monitoring sont compatibles ?
Tout outil qui peut envoyer un courriel ou faire un appel HTTP : Zabbix, Nagios, Datadog, PRTG, AWS CloudWatch, Azure Monitor, Google Ops, sondes SOC, SIEM. Chaque groupe IPA a son courriel dédié et son webhook — vous pointez, ça marche.
Combien de temps pour intégrer ?
Compte créé en quelques minutes. Configuration des premiers groupes et calendriers : 30 minutes. Intégration d'un outil de monitoring (ajouter le courriel dédié dans sa config) : quelques secondes par outil. Vous pouvez commencer à rediriger vos alertes critiques aujourd'hui même.
Cascade automatique : quels paramètres ?
Vous configurez le délai (ex: 3 min sans réponse → cascade), le nombre de personnes à contacter en parallèle, l'ordre d'escalade (technicien → relève → groupe → autre groupe), et les règles par type d'incident. Si la cascade épuise tous les niveaux sans réponse, l'administrateur est alerté automatiquement. Entièrement configurable sans code.
App sur smartphones personnels ou corporate ?
Les deux fonctionnent. L'app est gratuite (iOS/Android), installation en 30 secondes. Chaque utilisateur contrôle ses propres paramètres (sonnerie, vibration, ON/OFF). Pas de MDM requis, pas de configuration centrale intrusive.
Comment fonctionne la tarification ?
Tarification par utilisateur inscrit, à partir de 4 $ / utilisateur / mois. App gratuite sur le téléphone de vos techniciens. Pas de contrat par poste, pas de matériel. Essai sans engagement.
Cybersécurité : nos données sont-elles protégées ?
Serveurs localisés au Québec, conformes à la Loi 25. Communications chiffrées TLS. IPA ne stocke que les messages d'alerte (pas de payload complet de vos courriels monitoring). Audit trail complet et exportable.
Vos outils envoient déjà des courriels — pas envie de coder une intégration ?
Pointez les courriels d'alerte de vos outils vers une adresse IPA dédiée. On convertit chaque email en alerte SMS, vocal ou push critique vers le bon technicien de garde, avec cascade automatique et accusé de réception. Aucune intégration API à coder, aucun webhook à configurer — passerelle email-to-SMS et email-to-voice native. Compatible avec tout outil qui peut envoyer un courriel : Zabbix, Nagios, Datadog, PRTG, AWS CloudWatch, Azure Monitor, sondes SOC, SIEM, ou simplement un script qui envoie un mail.
Support 365 × 24/7 — Infrastructure au Québec
La solidité qu'exige une infrastructure critique.
Support humain 24/7
Notre équipe est joignable en tout temps. Pas de bot, pas de ticket perdu — des ingénieurs qui connaissent votre installation.
Hébergement au Québec
Serveurs localisés au Québec, conformes à la Loi 25. Vos données restent sur le sol canadien.
Infrastructure redondante
Serveurs redondants, sauvegardes chiffrées, surveillance 24/7. La disponibilité est notre premier engagement.
Essayez IPA dans votre équipe TI — sans engagement
Compte complet créé en quelques minutes. Configuration des groupes et intégration monitoring en quelques heures. Essai sans limite — vous ne reviendrez pas aux alertes perdues dans le bruit.